No, not like that time we put a Pico 2 in dry ice.
We made a thing. The Tufty 2350. It’s 320x240 pixels of wearable, hackable badge built around the RP2350, with 8MB of PSRAM and 16MB of flash. It’s part of our Badgeware lineup, which share the same architecture but each have their own unique display setup. Badger; a slow, methodical e-Ink display, Blinky; a rip roaring dash of white LEDs, and Tufty; pushing the RP2350 to its limits trying to crank 76k pixels of vector graphics at an acceptable framerate.

From slow, ambient information to eye-catching LEDs animations, we've got a hackable badge for everyone.
With so many pixels to push, Tufty needs to be fast. Unfortunately the last time we tried to make a Pico 2 go fast it involved solid carbon dioxide, a lot of nerve, and a clock speed I am not allowed to recommend (I work from home, so I missed that particular bit of office mischief).
This time nobody's hands got cold. No extreme overclocking (we bumped Tufty to 200MHz though), no exotic cooling, no voiding of warranties. Just a compiler flag, a config option, and too much coffee.
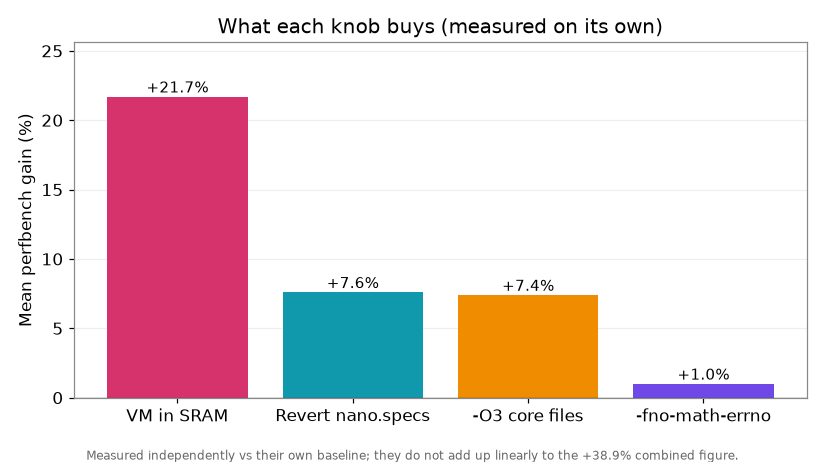
Since we’ve already tuned our custom vector graphics library (an ongoing effort) I turned to squeezing performance out of MicroPython itself. After some deliberation I got a stack of low-impact changes that add up to +38.9% mean across the standard perfbench suite, and one of them is so simple it hurts.
The test rig
Everything was measured on a Raspberry Pi Pico 2 (the plain RP2350 board) as a clean bench mule, using MicroPython's own tests/run-perfbench.py at N=150 M=100, averaged over 3 runs. Baseline is upstream micropython/master. Higher score = faster. No confounding factors from weird things we're doing with Tufty. Same basic Pico 2 board, same room, same pot of coffee.
I rebuilt and re-flashed for every change in isolation, and treated any difference under about 3% as noise unless it reproduced. A couple of "results" politely vanished the second time I ran them.
The one you should just take: -fno-math-errno
This one was a bit of a facepalm moment and another of the many, many things I didn’t catch when shouldering the MicroPython RP2350 port.
The Cortex-M33 in the RP2350 has a single-precision hardware FPU, and that FPU has a VSQRT.F32 instruction. One instruction. Square root. Done. So when MicroPython works out the magnitude of a complex number (which is just sqrt(re*re + im*im)) you would hope the compiler reaches for it.
It does not. By default GCC keeps sqrtf() as a call into a software routine, because the C standard insists sqrt must set errno on a domain error, and a lone hardware instruction cannot do that. So the compiler plays it safe and calls a whole library function; a square root, by committee.
The fix is to tell GCC we don't care about errno from maths functions:
target_compile_options(${MICROPY_TARGET} PRIVATE
-fno-math-errno
)
Is that safe? In MicroPython, yes. The math module never reads errno. It checks the result for NaN or infinity and raises ValueError itself:
// py/modmath.c
if ((isnan(ans) && !isnan(x)) || (isinf(ans) && !isinf(x))) {
math_error();
}
So math.sqrt(-1) still throws a ValueError, exactly as before. I confirmed it on hardware, then ran the full board test suite just to be sure nothing else twitched. All green.
After the flag, the complex-abs path collapses to this:
vsqrt.f32 s15, s15
The payoff lands where you would expect: about +16% on misc_mandel (a Mandelbrot set, which calls abs() on a complex number deep in its inner loop) and roughly nothing on benchmarks that never touch sqrt. And the binary got smaller, because one instruction.. is smol.
Smaller, faster, identical behaviour, passes the tests, speeds up some vec2 operations. That is about as close to a free lunch as you get, so we have raised as a pull request upstream. Enjoy!
The big one: run the interpreter from SRAM
On the RP2350 your code typically lives in external QSPI flash and runs through a small XIP cache. When that cache misses, the CPU sits there twiddling its thumbs waiting on flash. The single hottest lump of code in the entire system, the bytecode dispatch loop in py/vm.c, was running from flash like everything else.
MicroPython already has the hook to fix this. It was just never switched on for rp2. The MICROPY_WRAP_MP_EXECUTE_BYTECODE macro lets a port wrap the VM function, and the pico-sdk hands us __not_in_flash_func to park a function in SRAM:
#define MICROPY_WRAP_MP_EXECUTE_BYTECODE(f) __not_in_flash_func(f)
On its own, that is already a solid win. But the VM does not work alone. It calls a handful of leaf functions constantly: binary ops, attribute and global lookups, the map hash lookup, type checks. Parking those in SRAM is what really moved the needle:
#define MICROPY_WRAP_MP_BINARY_OP(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_LOAD_GLOBAL(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_LOAD_NAME(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_MAP_LOOKUP(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_OBJ_GET_TYPE(f) __not_in_flash_func(f)
Together: +21.7% mean. The leaf functions roughly tripled the gain over moving the VM loop alone, which tells you the real bottleneck on this chip is flash cache pressure, not raw clock cycles.
The cost is about 6KB of SRAM. On a 520KB chip that is practically a rounding error, but MicroPython upstream prefer to make tradeoffs like this optional. I'm not sure there's a good way to make this fit upstream, but any vendor who wants speed vs SRAM can chuck these six lines into their board config.
Update: It turns out that the linker scripts for RP2040 and RP2350 intended to do this all along, but due to a bug matching the object files that CMake produces it never happened. This compounded with another linker script bug - a single errant space - which came from upstream Pico SDK. I've raised a PR upstream to correct the scripts and restore the "correct" behaviour without needing to use the wrappers. That said these wrappers offer more fine-gained, opt-in control without delving into the arcane depths of linker scripts- so perhaps they're a better fit.
Another free 7%: just compile it harder
The rp2 port builds at -Os (optimise for size), with a short allow-list of hot files nudged up to -O2. Those three files (vm.c, map.c, mpz.c) are the interpreter core, the dict and map machinery, and the big-integer code. Bumping just them to -O3:
set_source_files_properties(
${MICROPY_PY_DIR}/map.c
${MICROPY_PY_DIR}/mpz.c
${MICROPY_PY_DIR}/vm.c
PROPERTIES
COMPILE_OPTIONS "-O3"
)
One character. 2 becomes 3. Worth +7.4% mean for about 2KB of flash. I am not going to pretend I agonised over that one.
The plot twist: a "size win" that quietly cost us 8%
This is the bit I did not see coming, made all the worse because it was my own doing.
A recent PR landed upstream to build the rp2 port with nano.specs (newlib-nano), to shrink the binary using smaller but not necessarily faster code. I had petitioned for upstream to add this without fully understanding the implications. Ooof. I had also been carrying it downstream for years to claw back flash on our RP2040 builds, it worked a treat, and when we moved to the RP2350 I brought it along and deployed it to our products without a second thought. What I had somehow never done was benchmark it on the new chip.
It does shrink the binary, by about 1.6KB (or closer to 50k on our batteries included builds). It also makes the interpreter slower across the board, and in one case dramatically so. bm_pidigits (big-integer arithmetic) dropped almost 30%. Most other benchmarks shed a few percent each. Free heap and static RAM did not budge at all, which was the giveaway.
The mechanism is wonderfully daft. newlib-nano swaps the optimised, word-at-a-time mem* routines for tiny byte-at-a-time ones:
| routine | full newlib | nano.specs |
|---|---|---|
memcpy | 236 B | 26 B |
memset | 134 B | 16 B |
memmove | 292 B | 50 B |
Tiny code. Slow code. And MicroPython shifts a lot of bytes around. So everything that touches memory got a bit (or a lot) slower in exchange for 1.6KB of flash that a 16MB board will never miss. The credit for spotting this belongs to a Raspberry Pi engineer who dropped by the PR and mentioned the performance hit in passing. As my grandfather always used to say: don’t assume, check.
If nothing else a least our slow memset helped me sniff out a double zero init bug in MicroPython.
Adding it all up
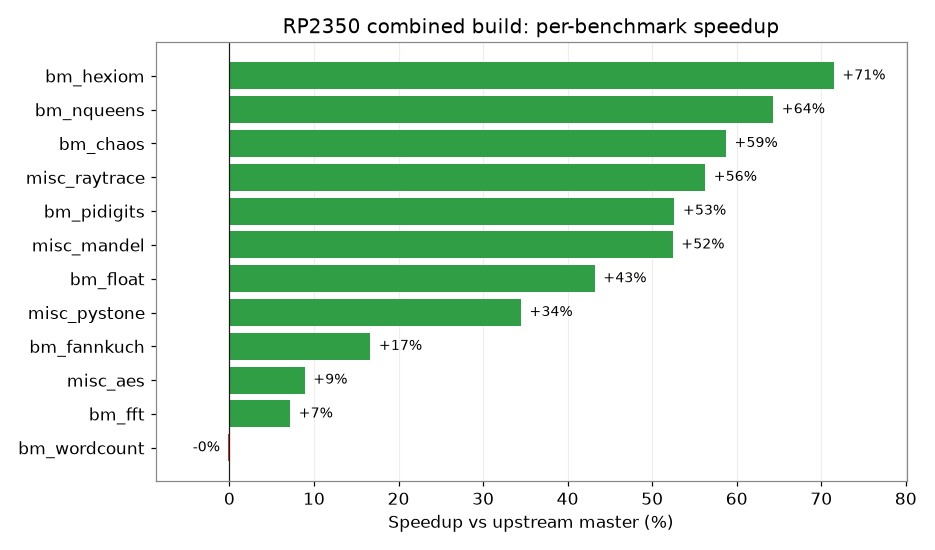
Stack all four (VM in SRAM, -O3, -fno-math-errno, and reverting nano.specs) and you land at +38.9% mean, with the call-and-branch-heavy benchmarks taking the biggest leaps.
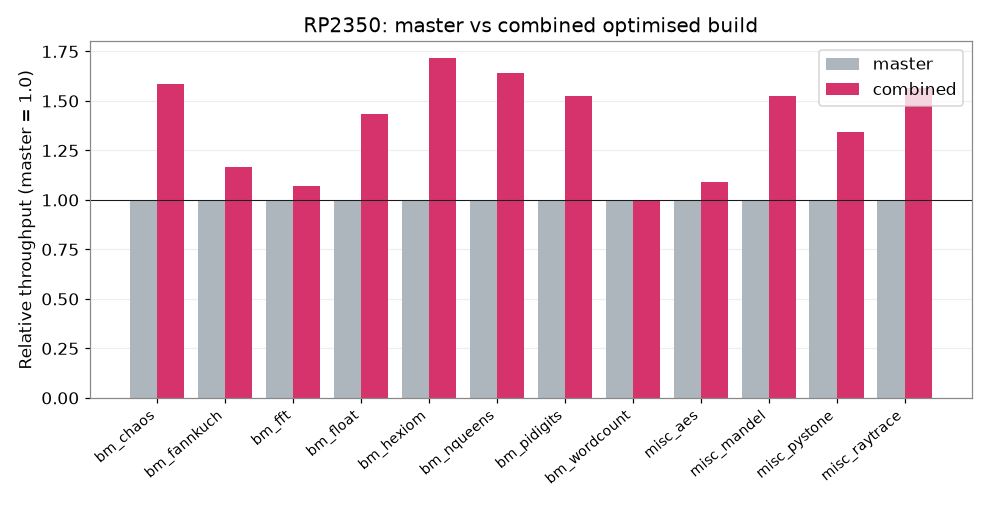
A rough sense of whodunnit (measured independently):
And the cost:
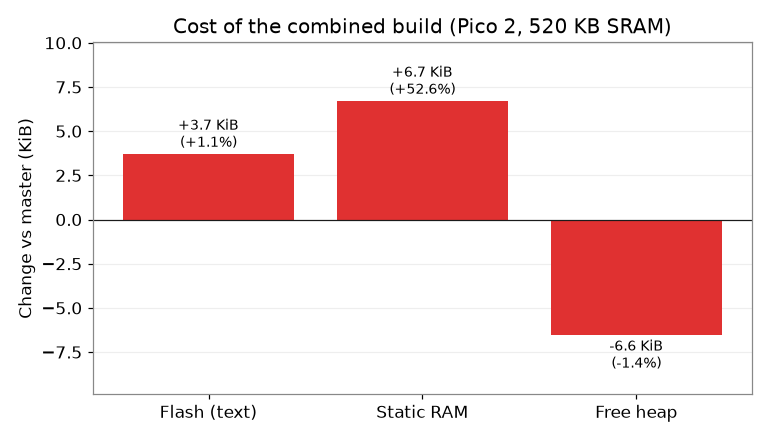
About 4KB more flash and roughly 7KB less heap. On a 520KB chip with multiple MB of flash, you'll be hard pressed to notice. Add 8MB of PSRAM and the SRAM is just another cache level!
For vendors and hobbyists: turning the knobs on a custom branch
Upstream's defaults are tuned for the smallest, most universal build, and that is the correct call for the project (and part of the reason why CircuitPython exists). But if you are shipping a board with headroom (say, an RP2350 next to PSRAM and 16MB of flash, like the Tufty 2350) you can trade some of that space back for speed. Here is the menu, cheapest first.
1. Take -fno-math-errno. No tradeoff, helps sqrt-heavy code, shrinks the binary. This one is in an upstream PR, so with any luck you will not even need to carry it downstream.
2. Compile the hot files at -O3. Costs about 2KB of flash. In ports/rp2/CMakeLists.txt, change the existing -O2 allow-list for map.c/mpz.c/vm.c to -O3.
3. Run the interpreter from SRAM. Costs about 6KB of SRAM. Just six lines in your board's mpconfigboard.h:
#define MICROPY_WRAP_MP_EXECUTE_BYTECODE(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_BINARY_OP(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_LOAD_GLOBAL(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_LOAD_NAME(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_MAP_LOOKUP(f) __not_in_flash_func(f)
#define MICROPY_WRAP_MP_OBJ_GET_TYPE(f) __not_in_flash_func(f)
This is the single biggest lever, and conveniently it is the one that gets cheaper the more memory you have. Which brings us neatly to...
4. If you have PSRAM, put the heap there. This is the move that stops the SRAM cost of (3) stinging. We lean on internal SRAM hard across our boards. Presto fills nearly all of it with a framebuffer (making some of these optimisations a real tradeoff). Tufty also uses SRAM for its framebuffer and also keeps a static SRAM pool that Picovector, PNGDEC and JPEGDEC carve their working buffers out of (allocating from a fixed pool is far cheaper than going through the heap, and it does not fragment).
Adding PSRAM lets you treat SRAM like another cache. Move the MicroPython GC heap into it and your Python objects go with it, freeing up internal SRAM for the framebuffers and static pools that actually need to be fast.
5. Skip nano.specs. If your flash budget is comfortable, do not pay ~8% of your interpreter speed to save 1.6KB. Build with full newlib and keep the fast mem* routines. Admittedly most of you won’t have made this mistake in the first place!
Stack 1 through 5 and that is the +38.9% build.
What is left on the table
A few avenues I have not chased yet:
- Inline caching for attribute and method lookups. A hefty architectural change: cache the last type-to-member mapping per call site and skip the hash lookup. This is done in CPython 3.11's "Adaptive Interpreter", and it would target object-heavy code. It is also a proper project rather than an afternoon, complete with fiddly cache invalidation. One for later.
- More hot C in SRAM. The one benchmark that flat-out refused to move through all of this is
bm_wordcount, which is bound by dict, string and GC work rather than dispatch. Parking those functions in SRAM too should finally shift it. Perhaps not by much, but easy to test.
But that is for another day. For now the Tufty 2350 is noticeably perkier, one of the fixes is on its way upstream for everybody, and I have learned that the lazy approach to MicroPython performance on the RP2350 - right after machine.freq(200_000_000) - is to keep the hot code out of flash. No liquid nitrogen or dry ice required.
All this performance tuning is for good reason, too. Tufty 2350‘s vector graphics setup is quite ambitious but we want to see how far we can push it. As such we have some shiny updates coming very soon- SVG parser, gradient fills, rounded caps, blur brush… stop me when I pique your interest. Check out badgewa.re if you want to learn more about our range of hackable badges. Come for the badge life. Stay for the brrr.